













- 홈
- Blogs
- Semiconductor
- What is a GPU? What is the relationship between GPU and graphics card?
What is a GPU? What is the relationship between GPU and graphics card?
GPU is a bustling market. Playing around GPU/graphics cards has also become a leisure pleasure for digital enthusiasts. It once challenged or even surpassed CPUs of the same period, drove countless game players crazy, and extended its tentacles to deeper and broader fields.

1. Those easily confused concepts
GPU (Graphics Processing Unit), also known as display core, visual processor, or display chip, is a microprocessor designed specifically for parallel processing and excels in handling a large number of simple tasks, including graphics and video rendering. GPU can be applied in various scenarios that require rendering graphics or high-performance computing, such as desktops, laptops, workstations, game consoles, embedded devices, data centers, etc.
In daily life, we commonly refer to GPUs as graphics cards. However, in fact, there are slight differences in terminology between GPU and graphics card. GPU refers to the chip responsible for processing various tasks, while graphics card refers to the board that brings together GPU chips, graphics memory, interfaces, etc.
GPUs are divided into integrated GPUs (iGPUs) and discrete GPUs (dGPUs) based on the way they are connected to the system. The former is what we commonly refer to as integrated graphics cards/core graphics cards, while the latter is what we commonly refer to as independent graphics cards. Both types of GPUs have their own characteristics and usage scenarios.
The two classification tables for GPUs are as follows
| Category | Integrated GPU | Discrete GPU |
| Alternative name | Integrated display, core display (core graphics card, specifically referring to integrated display placed on the same chip as the CPU) | Independent graphics card (independent display), dedicated graphics card, graphics card, video card, accelerator card (independent board for AI acceleration tasks) |
| Relationship with CPU | Embedded next to the CPU | Appearing as a standalone board, usually connected to a PCI high-speed interface |
| Memory | Share system memory with CPU | Using dedicated memory, i.e. graphics memory |
| price | Low (bound to CPU) | high |
| performance | Meet basic applications | Large graphics and image tasks |
| power dissipation | low | high |
| Typical Representative | Intel(iris Xe 96EU)、AMD (Radeon 680M) | INVIDIA(GeForce)、AMD(Radeon)、Intel(Arc) |
| Main functions | Meet the needs of most consumer application scenarios, can be customized or embedded in products, and can be used as a supplement to discrete GPUs | Large scale games, video rendering, graphics processing, accelerating artificial intelligence tasks |
In an integrated GPU, the GPU is embedded next to the CPU and does not have a separate memory group for graphics/video, sharing system memory with the CPU. Due to the integrated GPU being built into the processor, it typically consumes less power and generates less heat, thereby extending battery life.
Discrete GPUs appear entirely as independent boards, usually connected to PCI high-speed slots, just like motherboards containing CPUs. In addition to containing GPU chips, discrete GPUs also include a large number of components required to allow the GPU to run and connect to the rest of the system. Discrete GPUs have their own dedicated memory, as well as their own memory source and power supply, so their performance is higher than integrated GPUs. However, due to separation from the processor chip, it consumes more power and generates a large amount of heat.
2. From specialized to universal and then to fusion
Modern GPUs have two major functions: one is to serve as powerful graphics engines, and the other is to be used as highly parallel programmable processors to handle various neural network or machine learning tasks.
Graphic computing is a GPU's specialty. When we drag the mouse, the GPU calculates the graphic content that needs to be displayed and presents it on the screen; When we open the player to watch a movie, the GPU decodes the compressed video information into raw data; When we play games, the GPU calculates and generates game graphics. Behind the light click of the mouse is a complex processing process, including vertex reading, vertex rendering, primitive assembly, rasterization, pixel rendering, and so on.
Graphics GPUs are widely used in games, image processing, cryptocurrency and other scenarios, focusing on parameter indicators such as frame count, rendering fidelity, and real-world scene mapping in graphics.
The following table describes the different stages of hardware acceleration for pipeline implementation defined by graphical APIs
| Stage | Details |
| Vertex Fetch | Retrieve vertex information from memory or graphics, including attributes such as position, color, texture coordinates, normal vectors, etc |
| Vertex Shader | Calculate coordinates and various attributes for each vertex |
| Primitive Assembly | Combine vertices into primitives, such as points, line segments, triangles, etc |
| Rasterization | Lattice vector graphics to obtain pixel points covered by elements, and calculate attribute interpolation coefficients and depth information |
| Fragment Shader | Perform attribute interpolation to calculate the color of each pixel |
| Per-Fragment Operation | Perform template testing, depth testing, color blending, and logical operations, and ultimately modify the rendering buffer |
Universal computing is the best embodiment of the advantages of GPU parallel computing. Scientists and engineers have found that as long as data exists in graphical form and GPU is added with some general computing power, GPU can be competent for various high-performance modular computing tasks, which is known as the General Purpose Graphics Processing Unit (GPGPGPU) in the industry. Essentially, a universal GPU is still a type of GPU, but it will be customized and aligned for high-performance computing, AI development, and many other amazing breakthroughs, resulting in a larger training set, shorter training time, lower classification/prediction/inference power, and less infrastructure usage.
General GPUs are mainly used in scenarios such as large-scale artificial intelligence computing, data centers, and supercomputing to support larger data volumes and concurrent throughput.
Behind the two major functions is a long history of development.
In 1962, Ivan Sutherland's paper "SketchPad: Graphical Human Computer Communication" and his recorded Sketchpad operation videos became the basis for defining modern computer graphics. In the following 20 years, due to limitations such as accuracy and operational intensity, graphics cards at that time only translated graphics generated by CPU calculations into display signals, so they could only be referred to as VGA cards. It wasn't until IBM introduced two 2D graphics cards, MDA and CGA, in 1984 that the industry took shape. Although these two products can only be considered ugly ducklings, they marked the beginning of GPU's path to compete with CPU.
In the 1990s, the rise of 3D graphics accelerated. After the first truly meaningful 3D graphics accelerator card in history, Voodoo, S3 released its first graphics card, the S3 Virgin, which has both 2D and 3D graphics processing capabilities. Since then, the industry has started to blossom in multiple directions, gradually giving birth to excellent products such as NVIDIA's NV1, Matrox's Millennium, Mystique, and PowerVR's PCX1, which once showed a grand competition among a hundred schools of thought. After the prosperity, there was a brutal trend of big fish swallowing small fish mergers and industry integration, forming the dominant pattern of NVIDIA and AMD. Since then, GPU has also embarked on a path of leapfrog iteration.
Development History of Independent Graphics Cards
| Year | Event |
| 1976 | Matrox, founded in Canada, is the oldest provider of graphic solutions |
| 1981 | IBM Launches Two Recognized Earliest 2D Graphics Cards: Monochrome Graphics (MDA) and Color Graphics (CGA) |
| 1984 | IBM Launches EGA Enhanced Graphics Adapter |
| 1985 | ATI was founded by four Canadian immigrants |
| 1987 | The VGA (Video Graphics Array) standard proposed by IBM has emerged |
| 1987 | Trident founded |
| 1988 | The Trident8900/9000 graphics card is released, which is the ancestor of all 3D graphics cards today |
| 1989 | S3Graphics was established to dominate the 2D graphics chip market |
| 1993 | Huang Renxun, Chris Malachowsky, and Curtis Prime co founded NVIDIA |
| 1994 | 3dfx Interactive was established, once monopolizing the 3D graphics card industry |
| 1995 | S3 Launches Trio64v+, the Peak of 2D Performance |
| 1995 | 3dfx releases Voodoo graphics card, the first truly 3D graphics accelerator card |
| 1995 | NVIDIA Launches Its First Product NV1 |
| 1996 | ATI Announces First 3D Accelerator 3DStage (1) |
| 1997 | The game console Atari 2600 first appeared with an Antic chip specifically designed for graphics output, which is the prototype of modern graphics cards |
| 1998 | Intel introduced i740, which was later improved and integrated into the 810 chipset (referred to as i752) |
| 1999 | NVIDIA introduces GPU terminology, defined as "a single chip processor with integrated transformation, lighting, triangulation/cropping, and rendering engines" GeForce 256 is the world's first GPU |
| 1999 | NVIDIA Launches RivaTNT2 (NV5), Defeating Voodoo3 to Make NVIDIA the New Graphics Card Dominator |
| 2000 | S3 acquired by VIA (Weisheng Electronics) for $322 million |
| 2000 | 3dfx was acquired by NVIDIA for $70 million in cash and 1 million in shares |
| 2002 | ATI Releases Radeon 9700Pro, the First Graphics Card to Support DirectX9 |
| 2003 | ATI's Most Classic Graphics Card Radeon 9550 Introduced |
| 2003 | Trident acquired by XGI (SiS Graphics Division) |
| 2006 | NVIDIA Releases CUDA Architecture |
| 2006 | ATI Announces Merger and Acquisition of XGI Technology's Graphics Chip Production and R&D Department |
| 2006 | ATI acquired by AMD for $5.4 billion |
| 2009 | Intel started the Larrabee program and announced its termination three months later |
| 2011 | VIA announces the sale of S3Graphics to HTC for $300 million |
| 2020 | NVIDIA Launches Ampere GPU Architecture |
| 2020 | Intel Returns to the Independent Graphics Card Market with Xe Architecture |
The universality of GPU is gradually revealed during iterations. From the 1990s to the early 21st century, in response to more complex and extensive graphics computing problems, the GPU mode was no longer a fixed graphics pipeline mode. The programmability of vertex processors, geometry processors, pixel and sub pixel processors in the graphics pipeline was enhanced, demonstrating universal computing capabilities. Subsequently, in order to solve the problem of GPU on-chip load balancing, the Unified Shader Processor replaced various programmable components, and the application of stream processors (a computing system that fully considers concurrency and communication in stream computing models) laid the foundation for GPU universal computing.
The rapid growth of GPUs in terms of programmability and computing power has attracted the attention of a large number of research groups, vying to map a large number of complex computational problems onto GPUs and positioning them as an alternative to traditional microprocessors in future high-performance computer systems [14]. The Tesla architecture developed by NVIDIA officially marks the development of GPUs towards universal GPUs, laying the foundation for their widespread application in the field of deep learning in the future.
The Path of GPU from Graphic Display to Universal Computing
| Time | Type | Relevant standards | Representative products | Basic feature | Significance |
| 1980s | graphic display | CGA,VGA | IBM 5150 | Raster generator | The earliest graphic display controller |
| Late 1980s | 2D acceleration | GDI,DirectFB | S3 86C911 | 2D primitive acceleration | Opening the Era of 2D Graphics Hardware Acceleration |
| In the early 1990s | Partial 3D acceleration | OpenGL(1.1~4.1), DirectX(6.0~11.0) | 3DLabs Glint300SX | Hardware T&L | The first 3D graphics acceleration chip for PC |
| Late 1990s | Fixed pipeline | NVIDIA GeForce256 | Fixed shader function | First proposed GPU concept | |
| 2004-2010 | Unified Shader | NVIDIA G80 | Multifunctional Shader | CUDA to be released together with G80 | |
| 2011~present | Universal computing | CUDA,OpenCL 1.2~2.0 | NVIDIA TESLA | Complete scientific calculations unrelated to graphic processing | NVIDIA has officially separated the GPU product line for computing |
Returning to the present, the specificity of GPUs in graphic computing and their universality towards artificial intelligence have sparked debate in the scientific community on whether to split the AI and 3D functions of GPUs into two types of DSA. GPU is dedicated to graphics computing with high efficiency, but only supports a few specific algorithms and models. It has good compatibility with general computing, but has poor efficiency and high power consumption.
The current consensus in the industry is that the "dual personality" exhibited by GPUs in graphical and general-purpose computing will gradually merge, and in the future, GPUs will no longer have functional boundaries, and will also have native differentiability and tensor acceleration capabilities.
So, what about later? From recent conferences, it can be seen that GPUs will develop in three major directions: high-performance computing (GPGPU), artificial intelligence computing (AI GPU), and more realistic graphics presentation (Ray Tracing GPU) with large-scale expansion of computing power. Among them, AI is the key, and the GPU hardware/software interface will make it the "CPU of the AI world". AI based rendering will make tensor acceleration the mainstream in GPUs.
Two major functions and applications of GPU
| Graph | Al | ||
| Application of Ray Tracing in Games | AI Framework and Applications | Al development and tools | AI in Scientific Computing |
| Industrial Design and Engineering | Data center, cloud computing, and graphics virtualization | Autonomous Machines: Robots and the Internet of Things | |
| Product rendering and ray tracing | Edge computing/Al+5G enabling industry | Autonomous driving and transportation | |
| Al Accelerated Graphics Application | Edge computing/Al+5G enabling industry | Smart healthcare and life sciences | |
3. Relationship between GPU and CPU
Although GPU is useful, it cannot be separated from the CPU. On the one hand, the GPU cannot work alone and needs to rely on the CPU to control calls; On the other hand, the architectures of the two are extremely different, and the construction purposes are also different.
The CPU will contain 4, 8, 16, or even more powerful cores, and almost all functions such as arithmetic logic units (ALU), floating-point processing units (FPUs), address generation units (AGUs), memory management units (MMUs), etc. will be encapsulated in one core. Generally speaking, the ALU of the computing unit in the CPU is about 25%, the logical control is 25%, and the cache cache is 50%. On the other hand, in GPUs, the ALU of the computing unit usually reaches 95%, while the cache cache is 5%.
Initially, GPUs were designed as specialized hardware to help CPUs accelerate graphics processing. Graphics rendering has extremely strong parallelism, requiring very intensive computation and huge data transmission bandwidth, so GPUs are designed to contain thousands of smaller cores. Each GPU's kernel can perform some simple calculations in parallel, and the kernel itself is not very intelligent. However, unlike CPUs with "one core makes it difficult to eight cores", GPUs can simultaneously use all cores to perform deep learning calculations such as convolution, ReLU, and pooling. In addition, GPU adopts a flexible storage hierarchy design and a two-level programming and compilation model.
Differences between GPU and CPU
| CPU | GPU |
| Central processing unit | Graphics processing unit |
| Multiple kernels (such as 16 cores and 32 threads) | Many graphics card cores |
| Low latency | High throughput |
| Suitable for serial processing | Suitable for parallel processing |
| Can complete some operations at once | Can complete thousands of operations simultaneously |
The different structural designs give GPUs their own expertise. The frequency of the GPU is only one-third of that of the CPU, but in each clock cycle, it can perform nearly 100 times more calculations in parallel than the CPU. Among a large number of parallel tasks, the GPU is much faster than the CPU, and for tasks with very low parallelism, the apparent speed will be much slower. In addition, compared to CPUs, GPUs typically have 5-10 times the memory bandwidth, but there is longer latency when accessing data, which results in GPUs doing better in predictable calculations but worse in unpredictable ones.
It can be seen that the CPU and GPU are complementary and non conflicting, with the former focusing on serial operations and the latter on parallel operations. For example, CPU can be understood as a PhD, not only knowledgeable, but also delving deeply into many problems, without which many difficult problems cannot be solved. And GPUs are tens of thousands of middle and high school students who only know simple arithmetic, but no matter how powerful a PhD is, it is impossible to calculate tens of thousands of simple arithmetic operations in an instant.

Opening the brief history of computing, a variety of digital chips have emerged, and each type of digital chip has a long history of development. Behind a computer is a computational problem, which involves scalar, vector, matrix, and spatial data types. GPUs and other digital chips inevitably intersect and overlap. Now, the CPU is still the same CPU, but the GPU can no longer be a GPU.
For a long time, there has been constant controversy over GPU, FPGA, and ASIC, which can form heterogeneous computing systems of "CPU+GPU", "CPU+FPGA", and "CPU+ASIC" respectively. At the same time, FPGA and ASIC manufacturers often compare their own products with GPU computing power in parallel, such as the NVIDIA Tesla A100, which often becomes a "combat power measurement unit", and CPU suitors are telling their advantages.
Rationally speaking, GPUs, FPGAs, and ASICs are all good experts in coordinating CPU computing. For both manufacturers and downstream users, their characteristics are completely different. Although they may exhibit stronger computing power or better power consumption in some application scenarios, the deployment process inevitably requires comprehensive consideration of TCO (total cost of ownership), construction difficulty, system compatibility, and other factors, making it difficult to judge which is stronger or weaker.
Comparison of Different Computing Devices
| Name | CPU | GPU | FPGA | ASIC |
| definition | Central Processing Unit | Image processor/parallel computing processor | Field Programmable Logic Gate Array | Dedicated processor |
| effect | Logical operations and task scheduling | Graphic Display/Neural Network Machine Learning | Customized algorithms and calculations are programmable | Customized algorithms and calculations |
| cost | high | high | high | low |
| Calculation type | Scalar operation | Vector operation | Sparse operation | Specific algorithms |
| Energy efficiency ratio | low | in | excellent | excellent |
| advantage | The most versatile, computable, and mature product | Strong peak computing power and mature products | High average performance, low power consumption, strong flexibility, and small time delay | Al has strong computing power, small size, light weight, low power consumption, and strong confidentiality |
| shortcoming | The calculation is relatively general and the computational power is relatively small | Low energy efficiency and high power consumption | High unit price for mass production, low peak computing power, and high programming difficulty | High initial investment cost, non editable, long research and development time, and high technical risk |
| On behalf of the manufacturer | Intel, AMD | NVIDIA, AMD, Intel | AMD, Intel | Google, Cambrian |
However, GPUs have relatively mature products, excellent peak computing power, and an unshakable position in graphic display, naturally catching up with the semiconductor craze and becoming the darling of the market.
Data shows that during the AI training phase, GPU accounts for approximately 64% of the market share, while FPGA and ASIC account for 22% and 14% respectively; In the inference stage, GPUs account for approximately 42% of the market, while FPGA and ASIC account for 34% and 24% respectively.
Performance requirements and specific indicators of AI chips in different application scenarios
| Application Scenario | Chip requirements | Typical computing power | Typical power consumption |
| terminal | Low power consumption, inference task oriented, cost sensitive | <8TOPS | <5W |
| Cloud based | High performance, both reasoning and training, high unit price | >30TOPS | >50W |
| Marginal end | Requirements should be between the terminal and the cloud, with reasoning as the main focus | 5TOPS~30TOPS | 4W~15W |
GPU is not only a vast business in the present, but also has infinite potential in the future.
According to Verified Market Research data, GPU will grow at a compound annual growth rate of 33.3% from $33 billion to $477.3 billion from 2021 to 2030.
The GPU will be made into various specifications according to the different power load requirements of the platform. For example, the typical power consumption of the GPU in mobile phones is 5W, while the typical power consumption in laptops is 150W. Each machine can reach 400W, and the data center is fully committed to performance. According to power consumption, the market is mainly divided into two types: desktop level and mobile level applications.
Both markets present a tripartite situation: the desktop GPU market is monopolized by NVIDIA, AMD, and Intel, while the mobile GPU market is monopolized by ARM, Imaging, and Qualcomm. At the software level, the aforementioned foreign companies have also provided support for a series of heterogeneous computing standards such as CUDA and OpenCL.
In terms of desktop products, graphics cards for PCs or games account for the majority of the market, with a share of over 50% in the data center.
According to Jon Peddie Research (JPR) data, in Q2 2022, the shipment volume of GPUs used by PCs (including integrated and independent graphics cards) was 84 million, with Intel's GPU market share reaching 68%, mainly due to Intel's extensive integration of core displays in desktop/laptop CPUs; AMD ranks second with a 17% share. This company has both Core Display and Mono Display, but Core Display clearly dominates, with Mono Display only accounting for about 3% of the overall PC market; Nvidia mainly focuses on the exclusive display market, so although it may seem like only 15% of the market share, it basically dominates the exclusive display market.
2022 Q2 PC Market GPU Supply Situation

NVIDIA is the absolute leader in independent GPUs worldwide. In the initial stage, NVIDIA's focus was on PC graphics processing business, and later expanded to fields such as intelligent terminals, autonomous driving, and AI algorithms, taking advantage of the trend of GPU universal use. From the Q2 2022 financial report, Nvidia's main businesses include gaming GPUs, data center GPUs, professional visual design GPUs, intelligent driving GPUs, as well as OEM and other businesses, accounting for 30.5%, 56.8%, 7.4%, 3.3%, and 2% respectively.
In order to better cope with competition, the architecture design of each generation of NVIDIA graphics cards has undergone significant changes. After analyzing the architecture of each generation of NVIDIA, it can be seen that the two core elements of performance improvement, Streaming Multiprocessor (SM) and Cache, have undergone significant design changes. This is to continuously adjust the configuration ratio of various components under the limited area and power consumption of the chip, and to seek the optimal solution through process iteration.
NVIDIA Architecture Changes
| Computing power | Architecture | Release date | Cores/SM | Total SM count | CUDA Cores | L1 Cache(KB) | L2 Cache(KB) |
| 1.0 | Tesla | - | - | - | - | - | |
| 2.0 | Fermi | 2009 | 32 | 16 SM | 512 | 48 | 768 |
| 3.0 | Kepler | 2012 | 192 | 15 SMX | 2880 | 48 | 1536 |
| 4.0 | - | - | - | - | - | ||
| 5.0 | Maxwell | 2014 | 128 | 24 SMM | 3072 | 96 | 2048 |
| 6.0 | Pascal | 2016 | 64 | 60 SM | 3840 | 64 | 4096 |
| 7.0 | Volta | 2018 | 648 Tensor Cores | 80 SM | 5120 | Share 128 with shared memory (up to 96) | 6144 |
| 7.5 | Turing | 2018 | 648 Tensor Cores | 72 SM | 4608 | Share 128 with shared memory (up to 96) | 6144 |
| 8.0 | Ampere | 2020 | 644 Tensor Cores | 108 SM | 6912 | Share 192 with shared memory (up to 164) | 40960 |
| 9.0 | Hopper | 2022 | 1284 Tensor Cores | 144 SM | 18432 | Share 256 with shared memory | 61440 |
Nvidia is the proposer of the GPU concept, and almost every product has sparked large-scale discussions among game enthusiasts and designers. Especially in the 40 series, the new Ada Lovelace architecture is used, using the TSMC 4N custom process, with a shader capacity of up to 83TFlops and an effective ray tracing computing power of 191TFlops, which is 2.8 times that of the previous generation product. There is also a fourth generation Tensor Cores, with an FP8 tensor processing performance of up to 1.32 PFlops, which is five times higher than the previous generation.
NVIDIA 30 Series and 40 Series Graphics Card Summary
| Model | GPU engine specifications | Memory specifications | Temperature and power specifications | |||||
| Number of CUDA cores | Acceleration frequency (GHz) | Basic frequency (GHz) | Standard graphics memory configuration | Bit | Maximum GPU temperature (℃) | Graphics card power (W) | Required system power (W) | |
| GeForce RTX 4090 | 16384 | 2.52 | 2.23 | 24 GB GDDR6X | 384 bits | 90 | 450 | 850 |
| GeForce RTX 4080(16GB) | 9728 | 2.51 | 2.21 | 16 GB GDDR6X | 256 bits | 90 | 320 | 750 |
| GeForce RTX 3090 Ti | 10752 | 1.86 | 1.67 | 24 GB GDDR6X | 384 bits | 92 | 450 | 850 |
| GeForce RTX 3090 | 10496 | 1.7 | 1.4 | 24 GB GDDR6X | 384 bits | 93 | 350 | 750 |
| GeForce RTX 3080 Ti | 10240 | 1.67 | 1.37 | 12 GB GDDR6X | 384 bits | 93 | 350 | 750 |
| GeForce RTX 3080 | 8960/8704 | 1.71 | 1.26/1.44 | 12GB/10 GB GDDR6X | 384 bits/320 bits | 93 | 350/320 | 750 |
| GeForce RTX 3070 Ti | 6144 | 1.77 | 1.58 | 8 GB GDDR6X | 256 bits | 93 | 290 | 750 |
| GeForce RTX 3070 | 5888 | 1.73 | 1.5 | 8 GB GDDR6 | 256 bits | 93 | 220 | 650 |
| GeForce RTX 3060 Ti | 4864 | 1.67 | 1.41 | 8 GB GDDR6 | 256 bits | 93 | 200 | 600 |
| GeForce RTX 3060 | 3584 | 1.78 | 1.32 | 12 GB GDDR6 | 192 digits | 93 | 170 | 550 |
| GeForce RTX3050 | 2560/2304 | 1.78/1.76 | 1.55/1.51 | 8 GB GDDR6 | 128 bit | 93 | 130 | 550 |
At the same time, NVIDIA is also an advocate for data center GPUs. Not only was it the first in the industry to launch a universal GPU product, but it also released the parallel programming model CUDA in 2006. The software and hardware base composed of a universal GPU and CUDA forms the foundation for NVIDIA to lead AI computing.
However, Nvidia's past few months have also been difficult. Affected by the continuous decline in demand in the semiconductor industry, there was a financial report avalanche and a sharp drop in stock prices. The newly released 40 series graphics card is also full of controversy, leading to Huang Renxun canceling the RTX 4080 12GB version.
AMD's GPU is primarily competitive in terms of cost-effectiveness. On independent GPUs, similar products are generally priced around 30% lower than NVIDIA. On integrated GPUs, APU products with core displays are cheaper than Intel CPUs with core displays.
In terms of nuclear display, according to Tom's Hardware test data, the AMD Ruilong series nuclear display performs excellently in many games.
Comparison of core graphics card performance

In terms of uniqueness, AMD has always been a follower of NVIDIA, and only in terms of floating point computing power, there is a certain gap with NVIDIA; In terms of actual performance, it is on par with Nvidia. To say which card is stronger or weaker, no one can give a final conclusion yet.
Performance Comparison of Independent Graphics Cards

In everyone's perception, Intel seems to be completely out of sync with GPUs, but in reality, it is the real leader in GPU shipments, thanks to its CPU occupying nearly 70% of the global PC market (including mobile laptops, desktops, and servers), and its core display has also been taken into various industries.
Share of global PC graphics processing unit (GPU) shipments by supplier from Q2 2009 to Q1 2022
 shipments by supplier from Q2 2009 to Q1 2022")
But like Intel, it has also repeatedly failed on independent GPUs.
Intel is definitely not a novice or amateur player in GPU. This company has the best GPU engineers in the industry, the best wafer fab, a bank account that others can only imagine, a globally renowned brand, and even holds the title of the world's largest GPU seller, with shipments greater than the total of its competitors. Perhaps for other companies, having such achievements is already satisfying, but Intel's repeated failures on independent GPUs over the past 20 years have left this company frustrated.
In 1998, Intel released a product called Intel i740, which performed well in 3D performance. However, among many other products such as ATI, NVIDIA, and S3 Graphics, it could only be considered qualified and had to temporarily give up the path of being unique.
Later in 2009, Intel did not give up its dream of becoming a standalone graphics processor and planned to build a Larrabee graphics processor. You should know that at that time, GPUs were just a combination of simple small computing cores, and Intel also happened to hold the P54C, the first generation processor core of the Pentium era. Integrating this core, which had a history of over 20 years at the time, into a graphics card may sound easy, but it is clear that the Larrabee research project still brought many troubles to Intel. After countless ticket hops and news of insufficient research funding, the plan ultimately failed. However, based on Larrabee research, Intel developed the Xeon Phi coprocessor with a Multi Core Architecture (MIC), which was selected by Tianhe 2. Therefore, Intel's efforts this time were not in vain.
In 2020, Intel was reborn, betting everything about independent graphics cards on the newly launched Xe architecture. In 2022, the Intel Arc (Ruixuan) series of graphics cards emerged, covering mobile, desktop, workstations, and data centers. Whether Intel can succeed this time still depends on subsequent market feedback.
The story of mobile grade products is not as rich and colorful as desktop grade GPUs, especially on mobile phones, tablets, and wearable devices. GPUs are highly bound to the architecture, and IP architectures such as Arm, Imaging, and Qualcomm Adreno each have supporters, making the landscape difficult to change dramatically.
From a product perspective, most of the GPU IPs used by MediaTek and Samsung's mobile SoCs come from ARM; Apple and Qualcomm's GPU IPs are self-developed (Apple's GPUs largely follow Imagination); Purple Light Zhanrui's SoC phone uses Imagination's GPU IP.
Ranking of smartphone and tablet GPU benchmark tests

{kind=link}
Articles you may also like
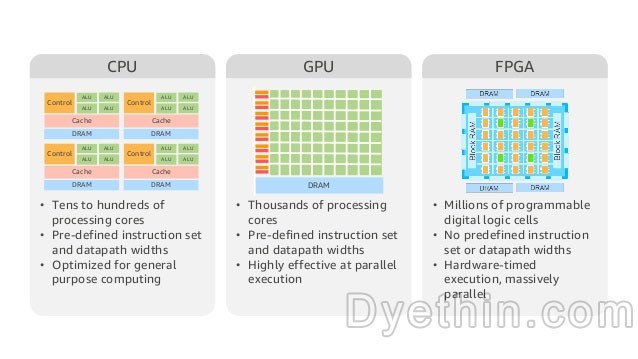
Characteristics of CPU, GPU, and FPGA

Silicon controlled rectifier (SCR) and switch control circuit explained

The difference between RAM ROM FLASH
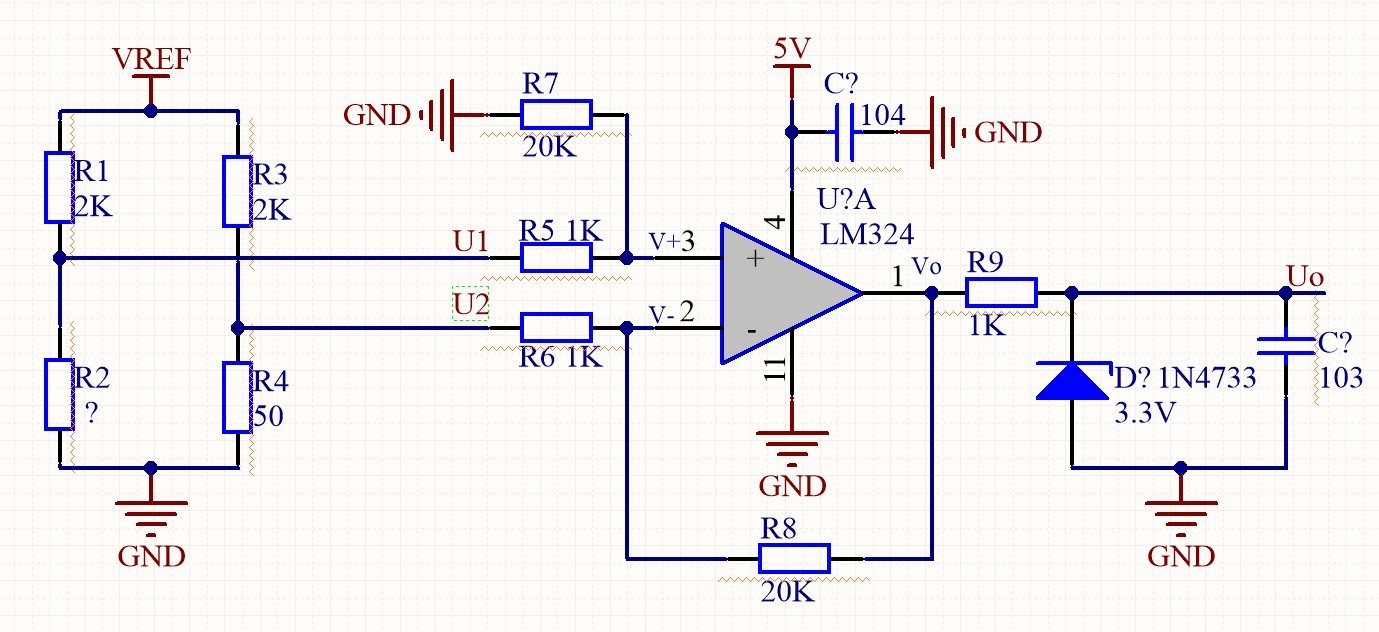
Accurately measure resistor value using ADC

-

-

-

-

-

-

texas-instruments
High-performance 200 MHz C2000 MCU with 1 MB Flash and advanced control peripherals
-

-

-
